Your website may be duplicating its own content without you even realizing it – and thereby possibly causing negative effects on your search-engine marketing performance.
Say that you are a company that sells widgets. One of your pages will list all of the widgets, say, by price in descending order while another will show them grouped by color. Most of the time, each specific widget will have its own product description – and therefore all of the product descriptions will be the same on both of the aforementioned pages. In other words, both of the pages of your website will have the same content.
Many marketers know that duplicate content is bad, especially in a digital-marketing world in which “content is king.” However, most people think about duplicate content in the wrong way – namely, that Google (and others) actively penalize websites that contain duplicate content. That’s not exactly true – only the websites of the most-heinous spammers are directly penalized.
Search engines want to display a wide variety of authoritative, relevant results because this practice allows for a better user experience. So, when Google sees two pages (whether from the same website or on two different websites) with duplicate content, the search engine will only show one of them in search results. It’s not that the not-shown page is penalized; it’s that it is removed from consideration. In our hypothetical example, only one of the two pages at the widget company’s website will appear in searches, say, for “widgets” because Google thinks the two pages are identical. And much of the search-marketing work – building backlinks and related efforts – done to benefit the second page may be lost.
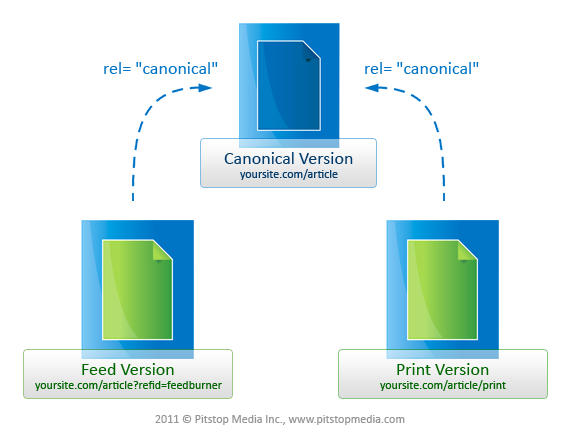
One solution is the rel=”canonical” link. As Google states:
If Google knows that these pages have the same content, we may index only one version for our search results. Our algorithms select the page we think best answers the user’s query. Now, however, users can specify a canonical page to search engines by adding a
<link>element with the attributerel="canonical"to the<head>section of the non-canonical version of the page. Adding this link and attribute lets site owners identify sets of identical content and suggest to Google: “Of all these pages with identical content, this page is the most useful. Please prioritize it in search results.”
In short, our widget company would want to choose which of its product pages Google should prioritize in search results, add the rel=“canonical” link, and then focus all inbound-marketing efforts on that specific page. (Another solution is to revamp all product pages so that all of them have unique content and target different keywords – after all, the more website pages that rank highly in Google, the higher the chances for more organic traffic.)
The rel=”canonical” link can also help to protect you from content theft and plagiarism by unscrupulous black-hat SEO marketers who steal content and then use it to try to rank highly in search engines – it takes effort to produce quality content, and these people are lazy (not that we’re biased).
Take a common victim of plagiarism: A major news-website like the New York Times. When you look at the source code for this page with a campaign-finance article, you will see the following rel=”canonical” link pictured at the top of this post. Countless bloggers and others copy large portions of articles – if not the entire articles themselves – from companies like the Times and then put the text in their own sites (either out of ignorance of the law or black-hat marketing efforts). However, the rel=“canonical” link tells Google at the moment of indexing that the content on this specific page (the Times’ website) is “canonical” – in other words, the original, authoritative source.
The linking item is also a useful tool for media companies, like the Times, that syndicate content. The same op-ed column may appear legally in hundreds of places, and the rel=”canonical” link helps to ensure that people searching for the article will see it on the Times’ website rather than another site that is syndicating the column. In addition, the Times could also use the tag to tell Google which version of the same article – say, the first page of a multi-page article or the longer, “single-page” version – to show in search results. (Though, based on a quick glance at the source code, it seems that the newspaper is not using this strategy.)
Content may be king – but originality and authoritativeness is queen. When more and more people aim to publish (or steal) quality content, it is increasingly important for Google to know that you deserve all of the credit – and rankings – for your original work. The rel=”canonical” tag is one way to do exactly that.